* 교재 : 파이썬 머신러닝 완벽 가이드
정렬, Aggregation 함수, GroupBy 적용
* DataFrame과 Series 모두 포함
≫ 정렬 (sort_values())
RDBMS SQL의 order by와 유사하다.
주요 입력 파라미터에는
- by : 특정 칼럼 입력 시 해당 칼럼으로 정렬 수행
- ascending : True는 오름차순, False는 내림차순
- inplace : False는 sort_values()를 호출한 데이터프레임은 그대로 유지하고 정렬된 데이터프레임을 결과로 반환. True는 호출한 데이터 프레임의 정렬 결과를 그대로 적용
titanic_df를 Name 칼럼으로 오름차순 정렬해보자.
여러 개의 칼럼으로 정렬하려면 리스트 형식으로 입력하면 된다.

≫ Aggregation 함수
min(), max(), sum(), count()
모든 칼럼에 해당 aggregation이 적용된다는 특징이 있다.

≫ groupby()
RDBMS SQL의 groupby와 비슷하지만 SQL의 경우 대상 칼럼을 모두 나열해야하지만 판다스에서는 대상 칼럼을 제외한 모든 칼럼에 해당 함수를 적용해야한다는 점이 다르다.
데이터프레임에 groupby를 호출하면 DataFrameGroupBy라는 또다른 형태의 데이터 프레임을 반환한다.

API기반으로 처리하다보니 SQL보다 유연성이 떨어진다.
서로 다른 aggregation함수를 적용할 경우에는 egg()내에 인자로 입력해서 사용해야한다.

결손 데이터 처리하기
≫ isna ()
NULL은 NaN으로 표시한다.
결손 데이터 여부를 True와 False로 확인한다.

≫ fillna()
결손 데이터를 다른 값으로 대체할 수 있다.
반환 값을 다시 받거나 inplace=True 파라미터를 추가해야 실제 데이터 세트 값이 변경된다는 점을 주의해야한다.
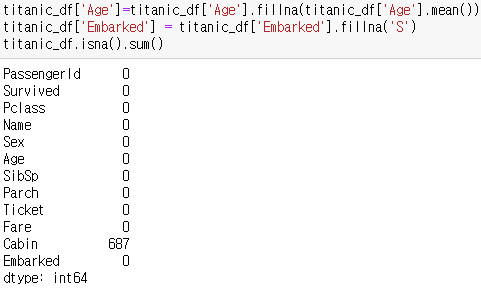
'Age' 컬럼의 NaN 값을 평균 나이로, 'Embarked' 칼럼의 NaN 값을 'S'로 대체해 모든 결손 데이터를 처리해보자.
'머신러닝' 카테고리의 다른 글
| [사이킷런] 사이킷런 소개와 붓꽃 품종 예측하기 (0) | 2021.06.02 |
|---|---|
| [Pandas] apply lambda 식으로 데이터 가공 (0) | 2021.06.01 |
| [OpenPose/텐서플로우] 윈도우에서 OpenPose 환경 구성 :: 근데 아나콘다를 곁들인 (0) | 2021.05.19 |
| [Pandas] Index 객체와 데이터 셀렉션 및 필터링 (0) | 2021.05.19 |
| [Pandas] DataFrame 객체 (0) | 2021.05.19 |



