판다스
: 파이썬에서 행과 열로 이뤄진 2차원 데이터를 효율적으로 가공/처리를 위해 존재하는 가장 인기 있는 라이브러리
DataFrame
여러 개의 행과 열로 이뤄진 2차원 데이터를 담는 데이터 구조체
칼럼이 여러 개인 데이터 구조체
Index를 key값으로 가지고 있음
여러 개의 Series로 이루어졌다고 할 수 있음
csv, tab : 분리 문자, 칼럼을 분리한 파일을 손쉽게 DataFrame으로 로딩할 수 있게 해줌
Index
개별 데이터를 고유하게 식별하는 Key 값 ex. RDBMS의 PK
인덱스는 단순 순차값 x, 고유성 보장
문자열도 가능
Series
칼럼이 하나 뿐인 데이터 구조체
Index를 key값으로 가지고 있음
파일을 DataFrame으로 로딩, 기본 API
https://www.kaggle.com/c/titanic/data?select=train.csv
주피터 노트북 디렉토리에 titanic_train.csv 이름으로 저장
DataFrame 로딩
read_csv()
read_csv(filepath_or_buffer, sep=" ,',...)
CSV 파일 포맷 변환을 위한 API, 필드 구분 문자가 콤마(',')
호출 시 파일명 인자로 들어온 파일을 로딩해 DataFrame 객체로 반환
파일의 맨 처음 로우를 칼럼명으로 인지하고 칼럼으로 변환
모든 DataFrame 내의 데이터는 생성되는 순간 고유의 Index 값을 가지게 됨
read_table() : 필드 구분 문자가 탭('\t')
read_fwf() : 고정 길이 기반의 칼럼 포맷을 DataFrame으로 로딩하기 위한 API
DataFrame.head()
맨 앞에 있는 N개의 로우 반환
DataFrame 크기, 분포도
shape 변수
DataFrame의 행과 열을 튜플 형태로 반환
info()
총 데이터 건수, 데이터 타입, Null 건수
describe()
칼럼별 숫자형 데이터값의 n-percentile 분포도, 평균값, 최댓값, 최솟값
숫자형 칼럼의 분포도만 조사
object 타입의 칼럼은 출력에서 제외
개략적인 수준의 분포도 확인 가능
[] 연산자
내부에 칼럼명 입력시 Series 형태로 특정 칼럼 데이터 세트 반환
value_counts()
해당 칼럼값의 유형과 건수 확인
지정된 칼럼의 데이터값 건수 반환
Series 객체에서만 정의되어 있음


DataFrame과 리스트, 딕셔너리, 넘파이 ndarray 상호 변환
사이킷런의 많은 API는 DataFrame을 인자로 입력 받을 수 있지만, 기본적으로 넘파이 ndarry를 입력 인자로 사용하는 경우가 대부분이다. 따라서 DataFrame과 ndarry 상호 간의 변환은 빈번하게 발생한다.
DataFrame은 기본적으로 행과 열을 가지는 2차원 데이터이기에 2차원 이하의 데이터들만 변환될 수 있다.
(1,2차원 형태의 리스트, ndarray/ 딕셔너리) - > DataFrame
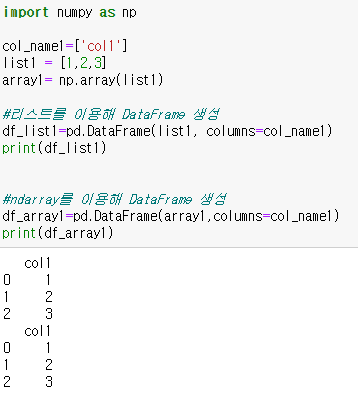
DataFrame - > (1,2차원 형태의 리스트, ndarray/ 딕셔너리)

DataFrame의 칼럼 데이터 세트 생성과 수정
Dataset의 칼럼 데이터 세트 생성과 수정 역시 [] 연산자를 이용해 쉽게 할 수 있다.
DataFrame [] 내에 새로운 칼럼명을 입력하고 값을 할당해주기만 하면 된다.

DataFrame 데이터 삭제
DateFrame의 데이터 삭제는 drop()메서드를 이용한다.
함수 원형은 다음과 같다.
DataFrame.drop(labels=None, axis=0, index=None, columns=None, level=None, inplace=False, errors='raise')
axis 값에 따라 특정 칼럼이나 행을 드롭한다. 0은 로우 방향 축, 1은 칼럼 방향 축이다.
axis 값이 0이면, labels에 오는 값을 자동으로 인덱스로 간주한다.
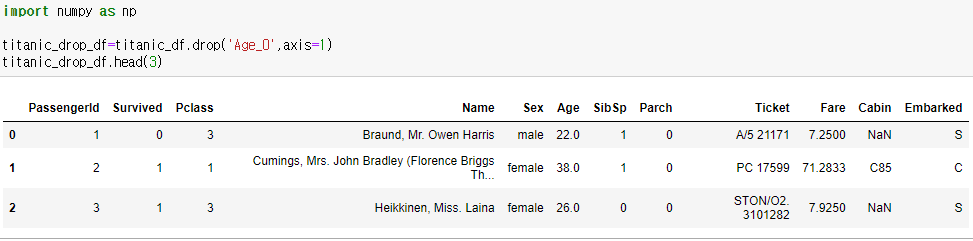
inplace 값에 따라 자기 자신의 데이터를 삭제할지 여부를 정한다. 기본 값은 False로, 자기 자신은 삭제되지 않는다.
'머신러닝' 카테고리의 다른 글
| [Pandas] apply lambda 식으로 데이터 가공 (0) | 2021.06.01 |
|---|---|
| [Pandas] 정렬, Aggregation, GroupBy, 결손 데이터 (0) | 2021.05.26 |
| [OpenPose/텐서플로우] 윈도우에서 OpenPose 환경 구성 :: 근데 아나콘다를 곁들인 (0) | 2021.05.19 |
| [Pandas] Index 객체와 데이터 셀렉션 및 필터링 (0) | 2021.05.19 |
| [numpy] ndarray, 행렬 정렬 (0) | 2021.05.05 |



